การที่ Pod ถูกลบออกจาก Kubernetes Cluster เกิดขึ้นในหลากหลายสถานกาณ์ ทั้งที่ผู้ใช้ลบเอง, ในขณะที่ kubectl drain เพื่อเหตุผลบางอย่างเช่นต้องการ update หรือในขั้นตอนการทำ RollingUpdate ซึ่งอาจดูเป็นเรื่องไม่สำคัญ และไม่มีผลกระทบอะไรมากนัก
แต่ในระบบขนาดใหญ่ที่มี node จำนวนมาก ต้องรองรับผู้ใช้งานปริมาณมหาศาล และยังต้องจัดการให้ user experience อยู่ในระดับดีมาก ช่วงเวลาเพียงเสี้ยววินาทีที่ pod ไม่สามารถใช้งานได้ แต่ผู้ใช้ยังพยายามที่จะติดต่อเข้ามายัง application ใน pod นั้น ก็อาจจะส่งผลกระทบในมุมลบในการให้บริการได้ การเข้าใจในกลไกในช่วงขณะที่ pod กำลังจะถูกลบ (Termination of Pods) อ่านเพิ่มเติมได้จาก Kubernetes ทำ Zero Downtime Deployment ให้เราจริงเหรอ?
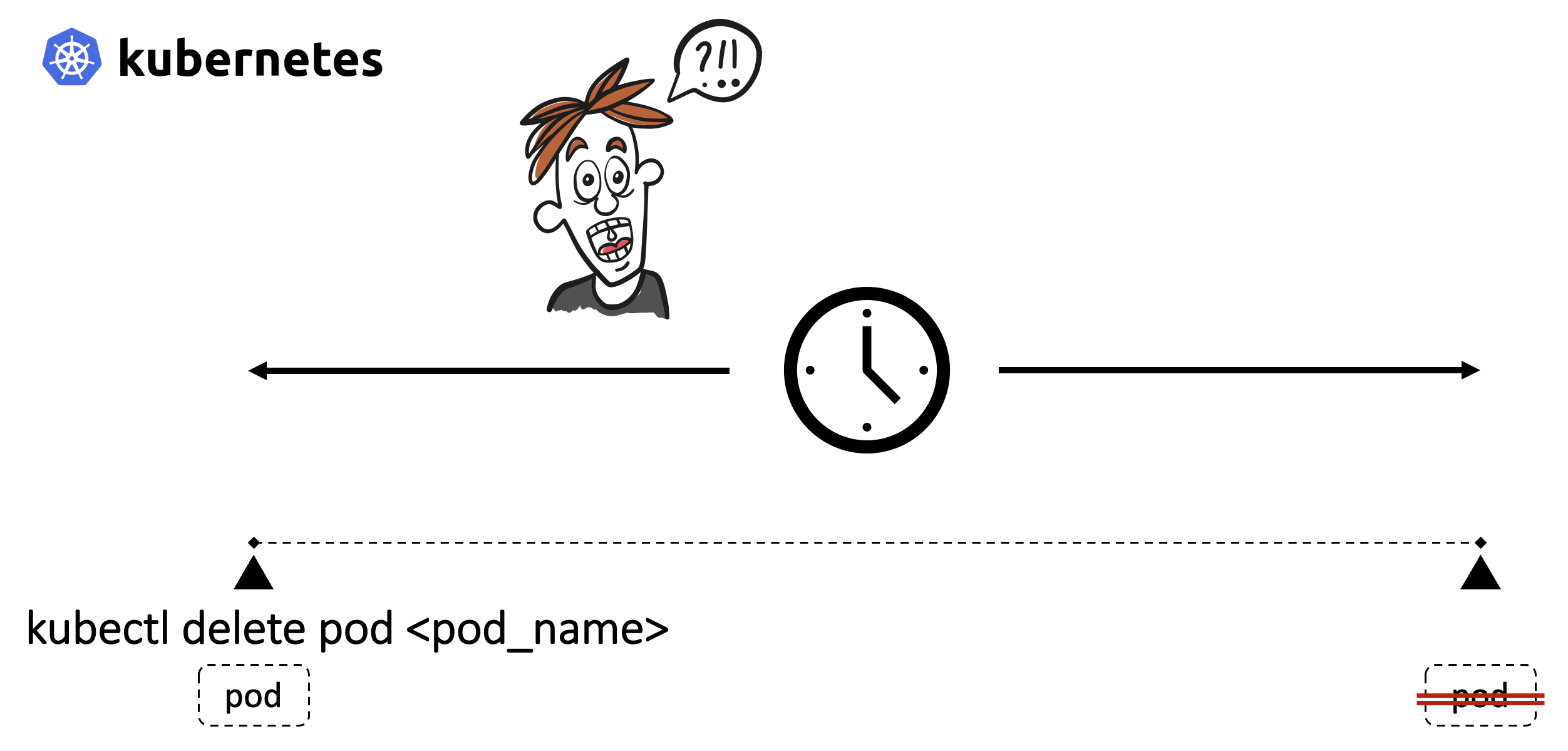
สมมุติว่า อ่านจบแล้ว … จะเห็นได้ว่า การเข้าใจกลไกในขั้นตอน Termination of Pods สามารถแก้ไข error ที่ผู้ใช้จะได้รับได้
ผมมีปัญหาอะไร ผมสงสัยอะไร!!!
ผมสงสัยว่า !!!
เวลาที่ kubernetes เริ่มนับที่เวลาที่รอการหยุดการทำงานที่เรียกว่า terminiation grace period จากตรงไหนกันแน่ เอกสารส่วนใหญ่ถูกเขียนไว้ว่า เริ่มนับตั้งแต่ในขั้นตอน preStop … แต่ตอนที่ผมทำการทดลอง พบว่ามันไม่ได้เป็นไปตามเอกสารที่เขียนผม … ผมทำผิดตรงไหน ผมเข้าใจอะไรผิด ขึ้นตอนการทดสอบผมผิดไหม ผลการทดสอบของผม ถึงออกมาเป็นอย่างนี้ … เรื่องราวในการทดสอบของผมทั้งหมด ก็จะประมาณนี้ครับ
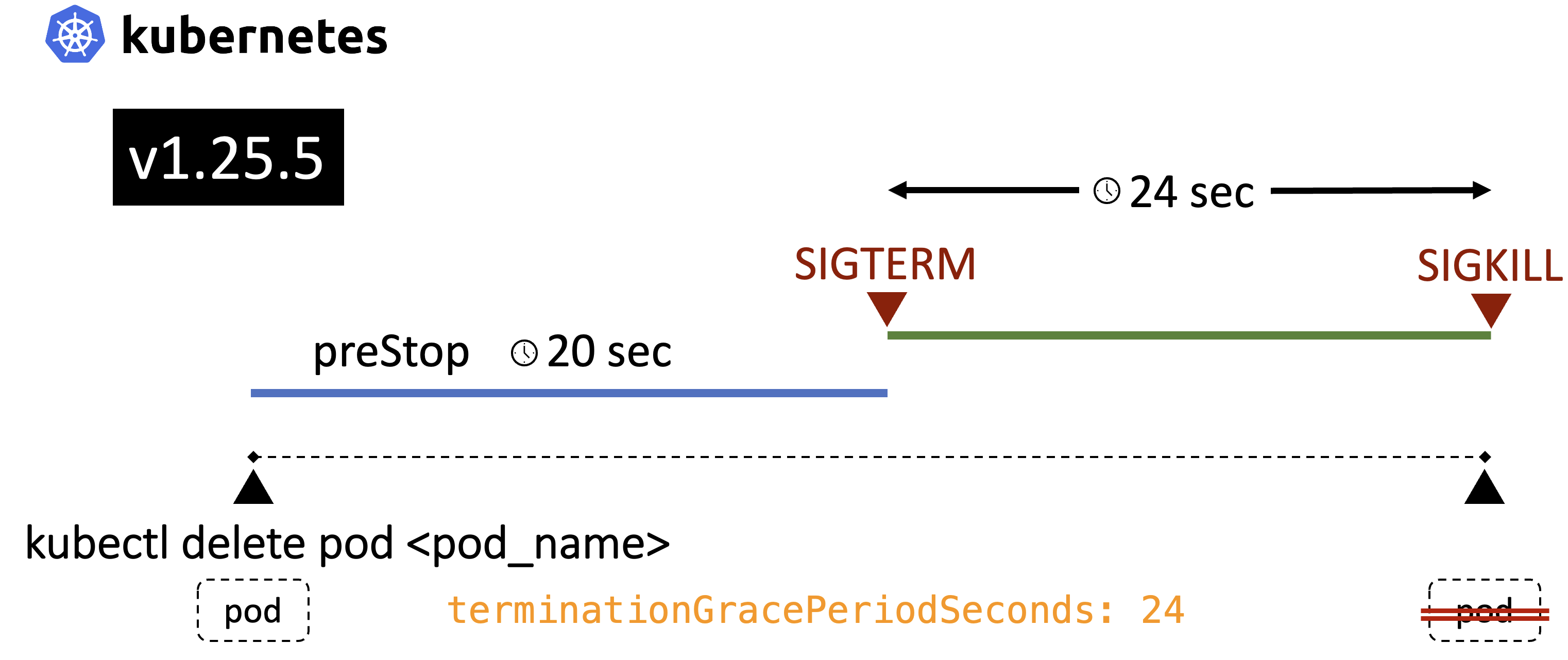
ทดสอบด้วย Kubernetes v1.25.5
d8k-a2m2 > preStop kubectl get nodes
NAME STATUS ROLES AGE VERSION
cluster4-cp0 Ready control-plane 6m27s v1.25.5
cluster4-cp1 Ready control-plane 4m16s v1.25.5
cluster4-cp2 Ready control-plane 4m17s v1.25.5
cluster4-node0 Ready <none> 6m5s v1.25.5
cluster4-node1 Ready <none> 6m5s v1.25.5
Pod Spec ที่ใช้ในการทดสอบ
pod ที่ใช้ในการทดสอบ ถูกเรียกจาก image ที่ชื่อว่า damrongsak/d8k-termloop ซึ่งในนั้นจะเป็นโปรแกรมที่เขียนด้วย python ที่ไม่ได้ทำงานใด ๆ แต่ถ้าได้รับ SIGTERM จะไม่หยุดการทำงาน แต่จะแสดงข้อความว่า “SIGTERM cannot kill me !!!” ออกมาทุก ๆ 1 วินาที ส่วน preStop.sh เป็น shell script ที่จะแสดงข้อความทุก ๆ 1 วินาที เป็นระยะเวลา 20 วินาที แล้วจึงหยุดทำงาน โดยที่กำหนดให้ terminationGracePeriodSeconds มีค่าเป็น 24 วินาที
apiVersion: v1
kind: Pod
metadata:
name: abc
spec:
terminationGracePeriodSeconds: 24
containers:
- image: damrongsak/d8k-termloop
name: abc
lifecycle:
preStop:
exec:
command: ["./preStop.sh"]
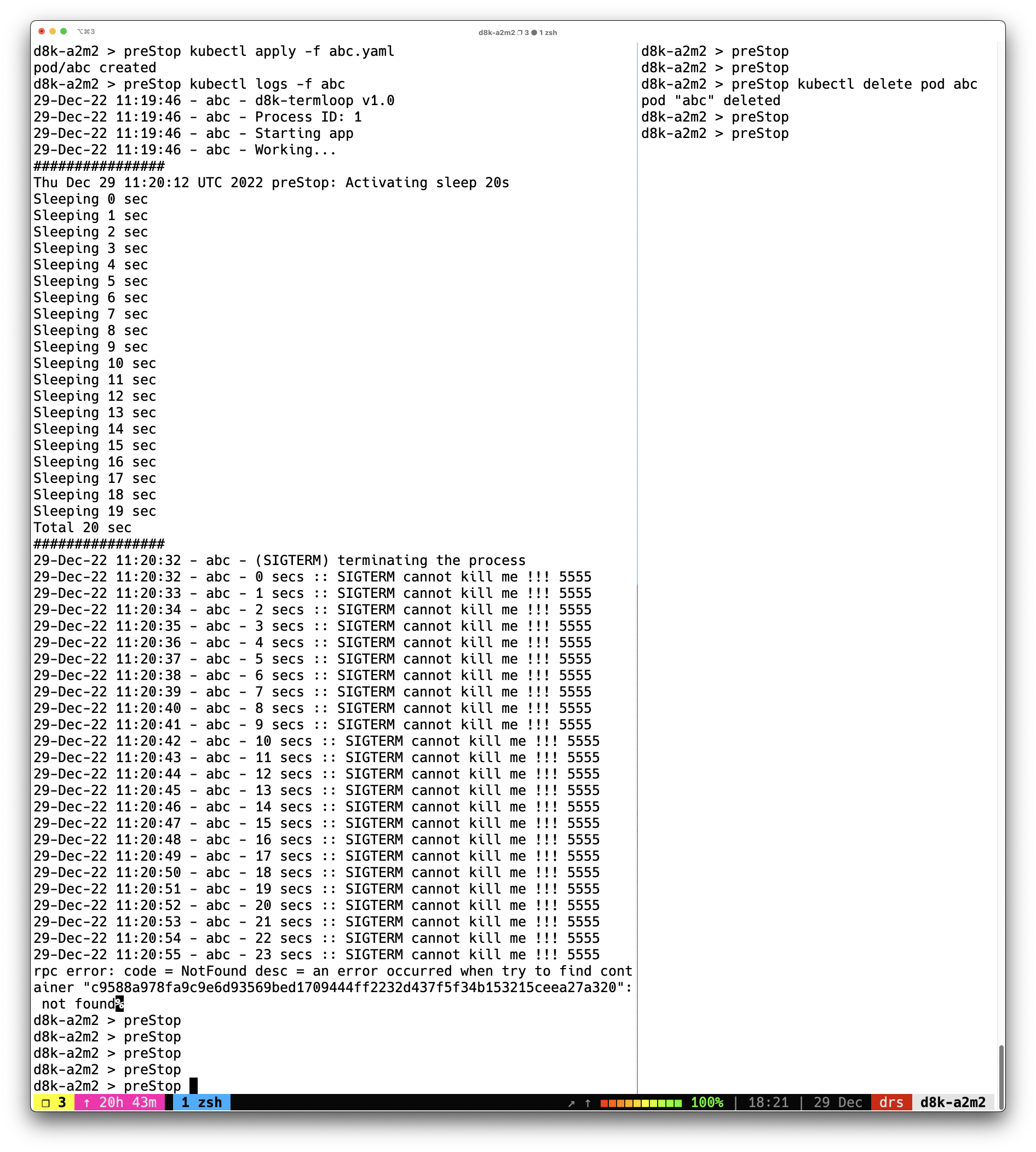
ผลการทดสอบ
 วิเคราะห์ผลการทดสอบ
วิเคราะห์ผลการทดสอบ
จากผลการทดสอบ เห็นว่าเมื่อส่งคำสั่ง
kubectl deletepod ก็เข้าสู่ขั้นตอน termination จากนั้น.spec.containers[].lifecycle.preStopก็เริ่มทำงานทันที เป็นระยะเวลา 20 วินาที หลังจากที่ preStop ทำงานเสร็จ SIGTERM ก็จะถูกส่งไป application ที่อยู่ใน container ใน pod แต่ก็จะเห็นว่า application ยังทำงานอยู่อีกเป็นเวลา 24 วินาที จึงหยุดทำงานจาก SIGKILL สังเกตุได้ว่า เวลาที่ application ยังทำงานอยู่หลังจากที่ได้รับ SIGTERM เป็นเวลาเท่ากับค่าที่กำหนดให้กับ termination grace period สรูปให้เข้าใจให้จำได้ง่าย ๆ ก็คือ termination grace period จะเริ่มนับตอนที่ preStop ทำงานจบ (แอบสปอยล์ไว้นิดหนึ่ง อย่าเพิ่งด่วนสรูปว่ามันจะเป็นอย่างนี้เสมอ ตอนท้ายมีการทดสอบไปรูปแบบอื่นอีก)
เริ่มต้นหาคำตอบ
เกิดอะไรขึ้น … ทำไมผลการทดสอบไม่เป็นไปตามทฤษฎี … ผมก็เริ่มทักน้องที่เขียนบทความเรื่องนั้น ทักไปยังเพื่อนพี่น้องที่เราคิดว่าคุ้นเคยกับ Kubernetes รวมถึงโพสต์ใน facebook ของตัวเอง … วันนั้นเป็นวันที่สนุกมาก ได้พูดคุยกับหลาย ๆ คน หลาย ๆ session แลกเปลี่ยนความคิดเห็นกันว่า ทำไมผลการทดสอบมันถึงออกมาเป็นอย่างนี้ … ระหว่างการพูดคุย น้องโจโจ้ จากเพจ Jumpbox ทักขึ้นมาว่า “พี่ทดสอบด้วย Kubernetes version อะไรเหรอครับ” เฮ้ย …. !!!! …. เราลืมนึกถึงตัวแปรเรื่องนี้ ก็เลยบอกน้องโจโจ้ไปว่า ขอเวลาพี่ 10 นาที ก็รีบไปสร้าง Kubernetes v1.19.xx ขี้นมาทดสอบ
ผลการทดสอบจาก Kubernetes v1.19.16
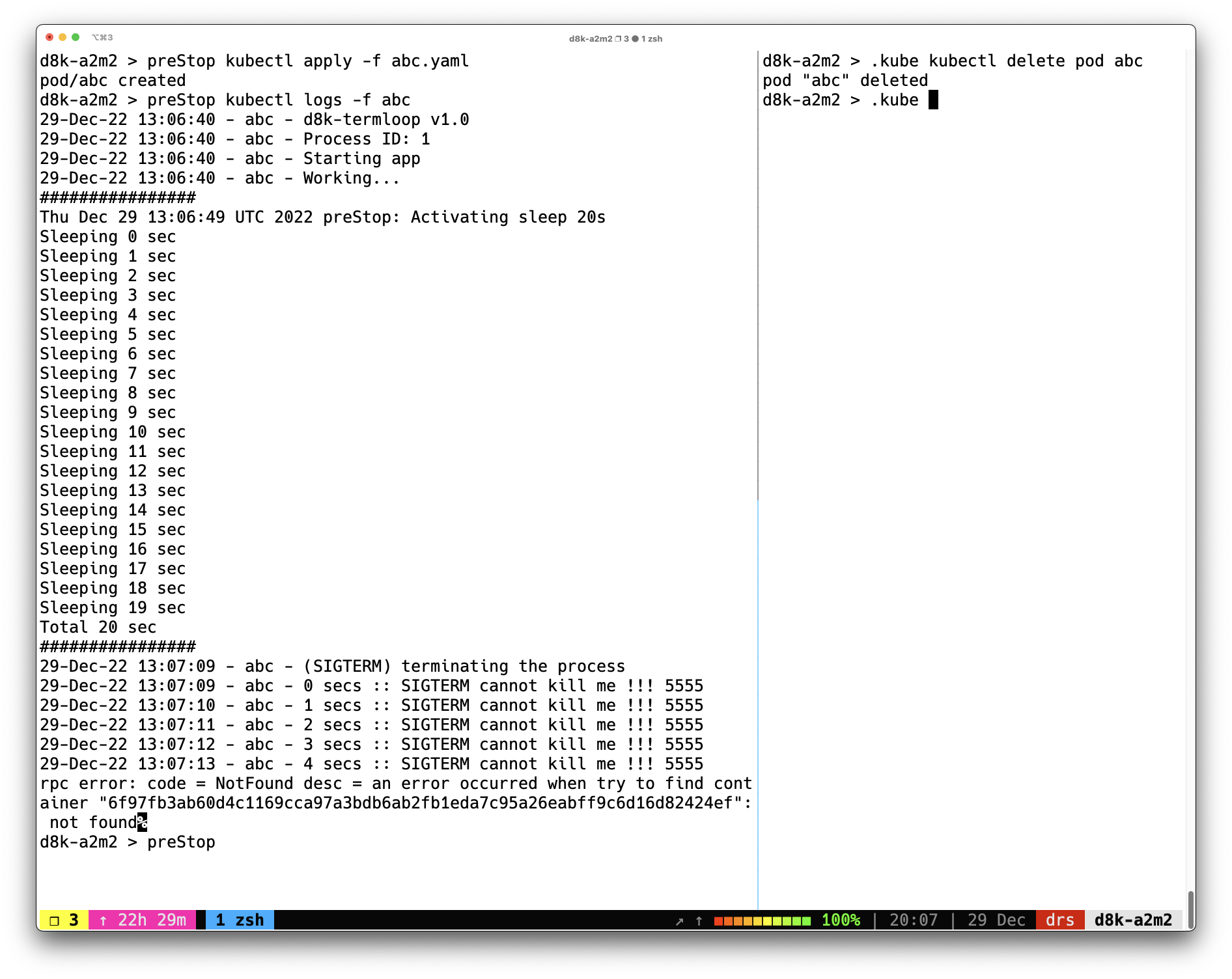
ปรากฎว่า ผลที่ได้ต่างจากสิ่งที่ผมทดสอบ แต่ว่าเป็นไปตามเอกสารที่มีอยู่ทั่วไป เมื่อส่งคำสั่ง
kubectl deletepod ก็เข้าสู่ขั้นตอน termination จากนั้น.spec.containers[].lifecycle.preStopก็เริ่มทำงานทันที เป็นระยะเวลา 20 วินาที หลังจากที่ preStop ทำงานเสร็จ SIGTERM ก็จะถูกส่งไป application ที่อยู่ใน container ใน pod แต่ก็จะเห็นว่า application ยังทำงานอยู่อีกเพียง 4 วินาที จึงหยุดทำงานจาก SIGKILL สังเกตุได้ว่า เวลาที่ preStop ทำงาน รวมกัน เวลา application ยังทำงานอยู่หลังจากที่ได้รับ SIGTERM เป็นเวลาเท่ากับค่าที่กำหนดให้กับ termination grace period สรูปให้เข้าใจให้จำได้ง่าย ๆ ก็คือ termination grace period จะเริ่มนับตอนที่ preStop เริ่มทำงาน
ความสงสัยยังไม่จบ
“แล้ววิธีการเริ่มจับเวลา termination grace period ที่ไม่เหมือนเดิม มันเริ่มเปลี่ยนแปลงมาตั้งแต่ Kubernetes version ไหน” … ผมก็เลยเริ่มค่อย ๆ ทดสอบ Kubernetes ทีละ version
| Kubernetes Version | When start termination grace period |
|---|---|
| v1.19 | preStop เริ่มทำงาน |
| v1.20 | preStop เริ่มทำงาน |
| v1.21 | preStop เริ่มทำงาน |
| v1.22 | preStop ทำงานจบ |
| v1.23 | preStop ทำงานจบ |
| v1.24 | preStop ทำงานจบ |
| v1.25 | preStop ทำงานจบ |
ความเปลี่ยนแปลงในการเริ่มนับ termination grace period เกิดขึ้นที่ v1.22
ถ้า ถ้า ถ้า ???
ถ้า preStop ทำงานนานมาก ๆ นานกว่า termination grace period จะเกิดอะไรเกิดขึ้น … จัดไปครับ ผมทำการทดสอบให้ 3 กรณี
- กรณีปกติ preStop ทำงานเสร็จ ใช้เวลาน้อยกว่า termination grace period [ t(preStop) < terminationGracePeriodSeconds ]
- กรณี preStop ทำงานเสร็จ ใช้เวลามากกว่า termination grace period แต่ น้อยกว่า 2 เท่าของ termination grace period [ t(preStop) < 2*terminationGracePeriodSeconds ]
- กรณี preStop ทำงานเสร็จ ใช้เวลามากกว่า termination grace period และ มากกว่า 2 เท่าของ termination grace period [ t(preStop) > terminationGracePeriodSeconds ]
ผลก็เป็นประมาณนี้ครับ
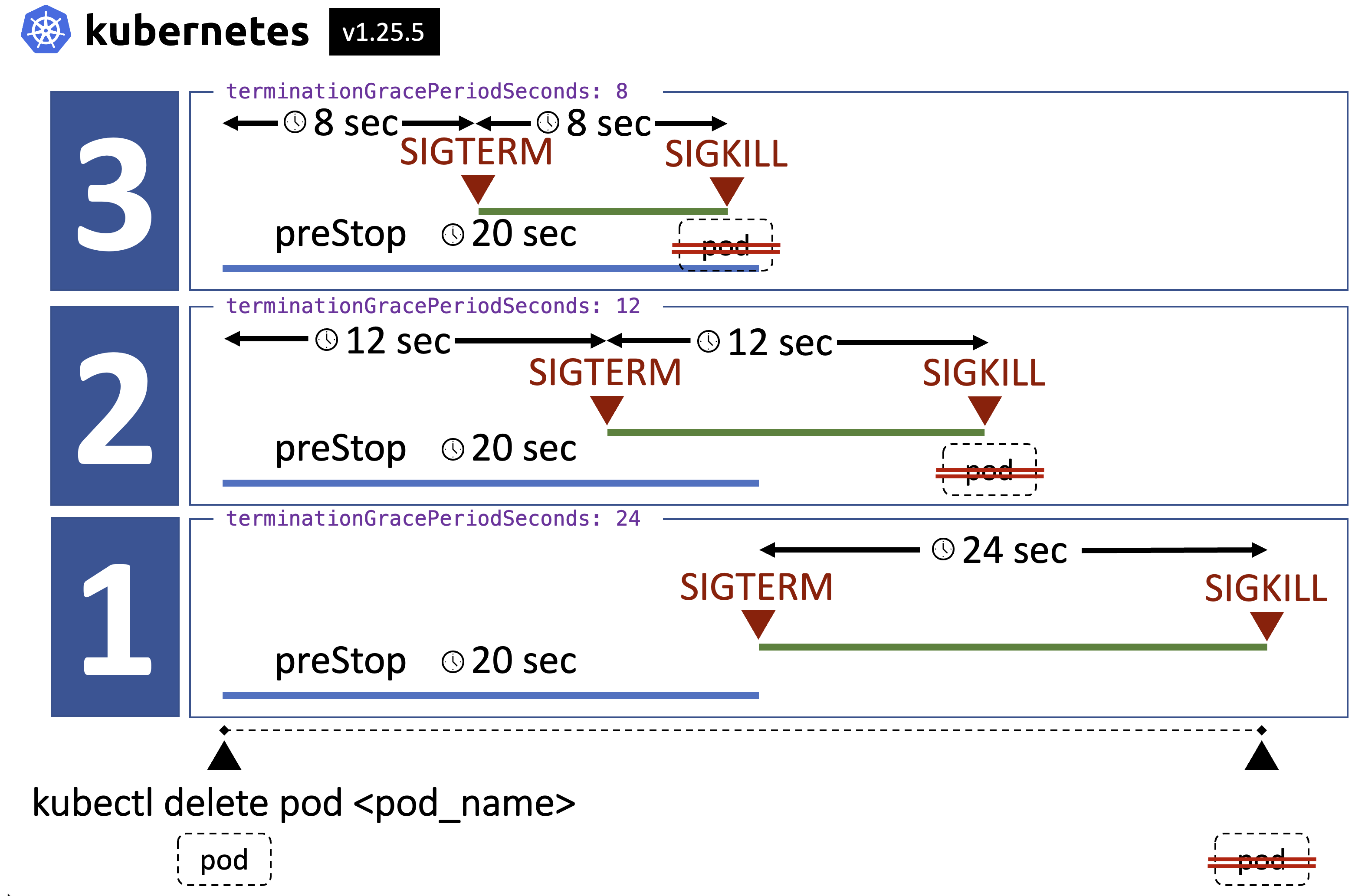
ประเด็นที่น่ากังวล คือเราตั้ง termination grace period สั้นมาก ๆ อาจจะทำให้ SIGKILL ถูกส่งออกมาก่อนที่ preStop จะทำงานเสร็จ อาจจะส่งผลกระทบจากที่คาดหวังไว้ก็ได้